

Working on adding a new compositor node, I ran into challenges with RNA. In a previous post, I discussed the difference between RNA and DNA, but I still didn’t fully understand DNA. It is hard to find examples of the DNA structure in any of the Blender documentation. For example, the DNA wiki page itself is blank. Therefore, I decided to dive into Blender DNA.
According to Ton Roosendaal, RNA and DNA are intended to be analogous to the biological meaning. DNA is the internal structure of the data and RNA is an API wrapper that allows you to get and set the data.
While trying to understand DNA, I came across a file in the source code called Mystery of the Blend. This document significantly helped my understanding of DNA.
Blender DNA Makes Blender Compatible and Fast
The Mystery of the Blend page, the comments by Ton Roosendaal, and others point out the speed and compatibility of Blender files. This is achieved by the way that Blender stores data in the files.
The Need for Speed
For speed, Blender saves blocks directly without any transformations. There are two examples that demonstrate this. Within the file header, Blender captures both endianness and pointer size. These are both system dependent. However, Blender doesn’t transform them into one standard. Instead, it notes in the header whether the system is big or little endian and whether the file is being saved with 32 or 64 bit pointers. This means you can have the exact same scene on two different computers resulting in different files. Although they are different files, they can open on the other computer.
Compatibility
The files are also highly compatible. This is because the information you need to read the file is contained within the file. Therefore, you can read older files in newer versions of Blender, and, in some cases, you may be able to read files saved with newer versions in old versions (although there may be some compatibility issues with new features such as this release note around compressed files in 3.0).
The Blender DNA Structures
I mentioned above that Blender stores the information needed to read the file in the file. This also helps us to understand the Blender DNA. The Blender dev wiki notes that the Main Database is “a runtime equivalent of the .blend file.”
The Blend file is composed of many data blocks. The key to reading those data blocks is the last data block of the file labeled SDNA for Structure DNA. This block lists all structures used in the file as well as information about the structure.
Within the same folder in the source code as The Mystery of the Blend, there is a Python tool, called BlendFileDnaExporter_25.py, that allows you to see the structures of a .blend file in HTML.
For example, the scene structure defines basic information about the scene.
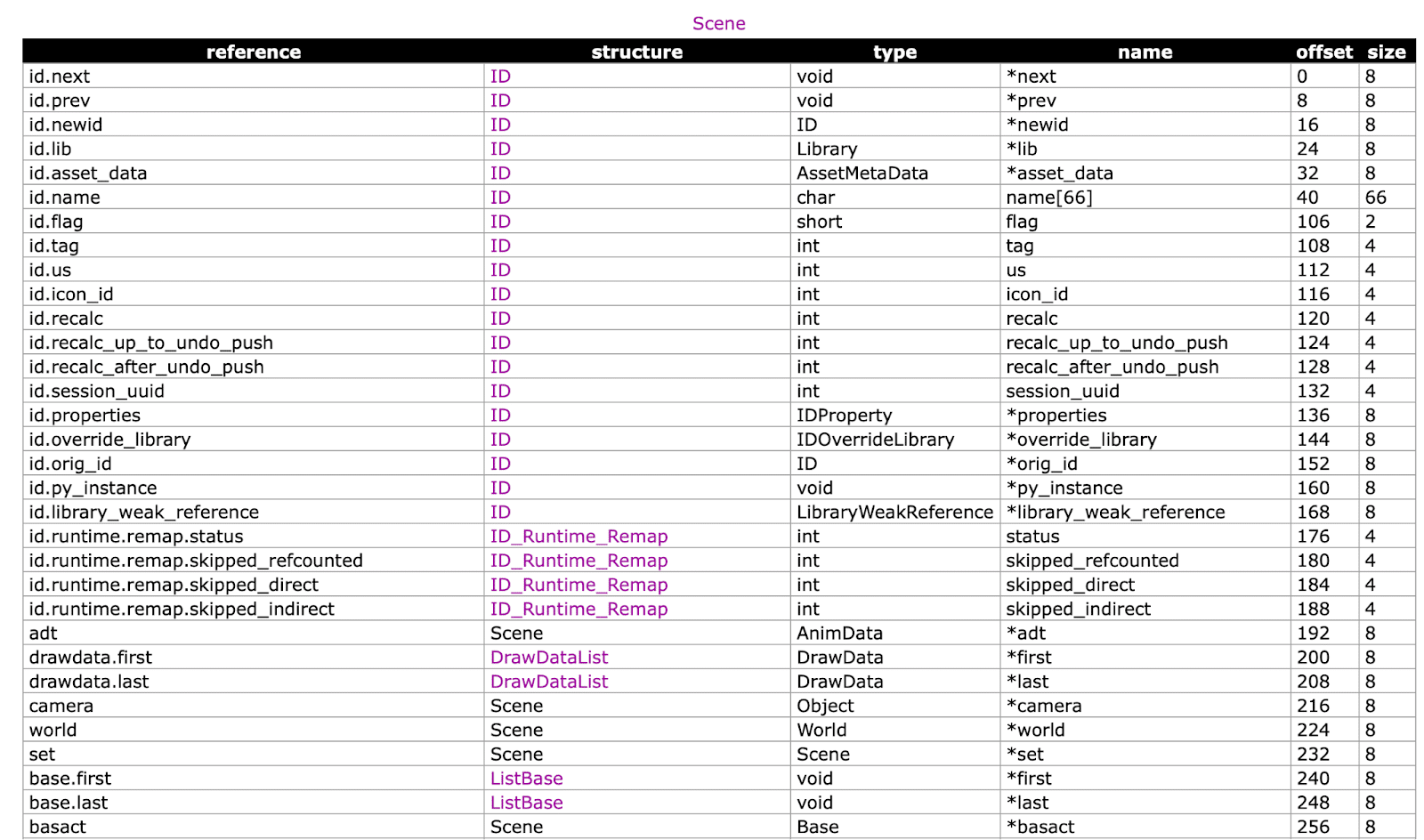
The screenshot above shows some of the fields in Scene. Further down in the structure are the elements r.xsch and r.ysch, which are the x and y resolution of the scene.

I wrote a quick, and messy, Python script to read just these elements in a .blend file.
import sys
class BlendFile:
def ReadFile(self, filename):
with open(filename,"rb") as self.f:
# first 12 bytes are the header
self.identifier = self.f.read(7).decode("ascii")
psize = self.f.read(1)
endianness = self.f.read(1).decode("ascii")
version = self.f.read(3).decode("ascii")
print("Identifier:", self.identifier)
if(psize.decode == '_'):
print("Pointer size is 4 bytes.")
self.pointerSize = 4
else:
print("Pointer size is 8 bytes.")
self.pointerSize = 8
bigEndian = (endianness == 'V')
if bigEndian:
print("Big Endian")
self.endian = 'big'
else:
print("Little Endian")
self.endian = 'little'
print("Version: ", version)
blockCount = 0
while self.ReadBlock():
blockCount += 1
def ReadBlock(self):
# Read the first 4 bytes, if 'ENDB', then we are done.
header = self.f.read(4).decode("ascii")
if(header == 'ENDB'):
print("End of file")
return False
blockSize = int.from_bytes(self.f.read(4),self.endian)
oldMemoryAddress = self.f.read(self.pointerSize)
sdnaIndex = int.from_bytes(self.f.read(4),self.endian)
count = int.from_bytes(self.f.read(4),self.endian)
# If the first 4 bytes are DNA1, then we have the SDNA section
if(header == 'DNA1'):
self.ReadSDNA()
return False
# If the header is SC, then we have the Scene structure
# We want to read the x and y resolution.
# I cheated on this by knowing the scene structure. Normally, you would
# read the structure from SDNA
if('SC' in header):
print("Header: ", header)
print("Block Size: ", blockSize)
print("SDNA:", sdnaIndex)
self.f.seek(40,1)
sc_name = self.f.read(66).decode("ascii")
# The x and y resolution are located at byte 888 of the block
self.f.seek(782,1)
x_res = int.from_bytes(self.f.read(4),self.endian)
y_res = int.from_bytes(self.f.read(4),self.endian)
print("Scene Name:", sc_name)
print("X:",x_res)
print("Y:",y_res)
self.f.seek(blockSize-888-8,1)
else:
self.f.seek(blockSize,1)
return True
# If you want to print the list of names, uncomment the print line below
def ReadSDNA(self):
# SDNA Header
id = self.f.read(4).decode("ascii")
nameID = self.f.read(4).decode("ascii")
numNames = int.from_bytes(self.f.read(4),self.endian)
names = self.ReadNames(numNames)
#print(names)
def ReadNames(self, number):
names = []
for _ in range(number):
currentName = ""
c = self.f.read(1).decode('ascii')
while(c != '\0'):
currentName += c
c = self.f.read(1).decode('ascii')
names.append(currentName)
return names
if __name__ == "__main__":
# check whether a blend file was provided
if (len(sys.argv) > 1):
filename = sys.argv[1]
blend = BlendFile()
blend.ReadFile(filename)
else:
print("Usage: python3 blendreader.py filename")So What?
The purpose of this post was just to better understand DNA and RNA. Now that we have the ability to examine the underlying DNA structure, it helps to better understand RNA. RNA provides a much simpler way to set properties. We don’t need to understand the underlying DNA structure.
In the previous section, we found the X and Y resolution of the scene in the DNA. However, we don’t need to do that to change the resolution by code. We can simply change using the following Python code.
bpy.data.scenes[“Test”].render.resolution_x = 1000
bpy.data.scenes[“Test”].render.resolution_y = 1000
RNA provides the benefit that almost everything within Blender can be accessed by script.
In our next post, we will continue the exploration of DNA and RNA by adding our own RNA property into the source code.


